
💳
Financial Services
Real-time transaction data pipelines, risk analytics infrastructure, regulatory reporting data marts, and fraud detection data feeds - built under applicable compliance frameworks including SOX and Basel III.

We build robust, scalable data engineering solutions - pipelines, cloud infrastructure, real-time processing, and DataOps - engineered around what your business actually needs to analyse, predict, and act on.
Our data engineering solutions power the analytics and AI your business depends on - built to scale from day one.
About UsAt CCPL.ai (CONFRONTIERS CONCLAVE), we build robust, scalable data infrastructure engineered around what your business actually needs to analyse, predict, and act on - not a generic technical template.
Without a solid data engineering foundation, every analytics dashboard and AI model is built on unstable ground. We fix that foundation - and build it to scale. Our solutions power the data analytics services and AI & ML solutions we deliver.
Most organisations have more data than they can use - not because the data doesn't exist, but because the infrastructure to collect, connect, and serve it reliably is missing. Siloed systems and absent quality controls are costing businesses insight they are already generating.
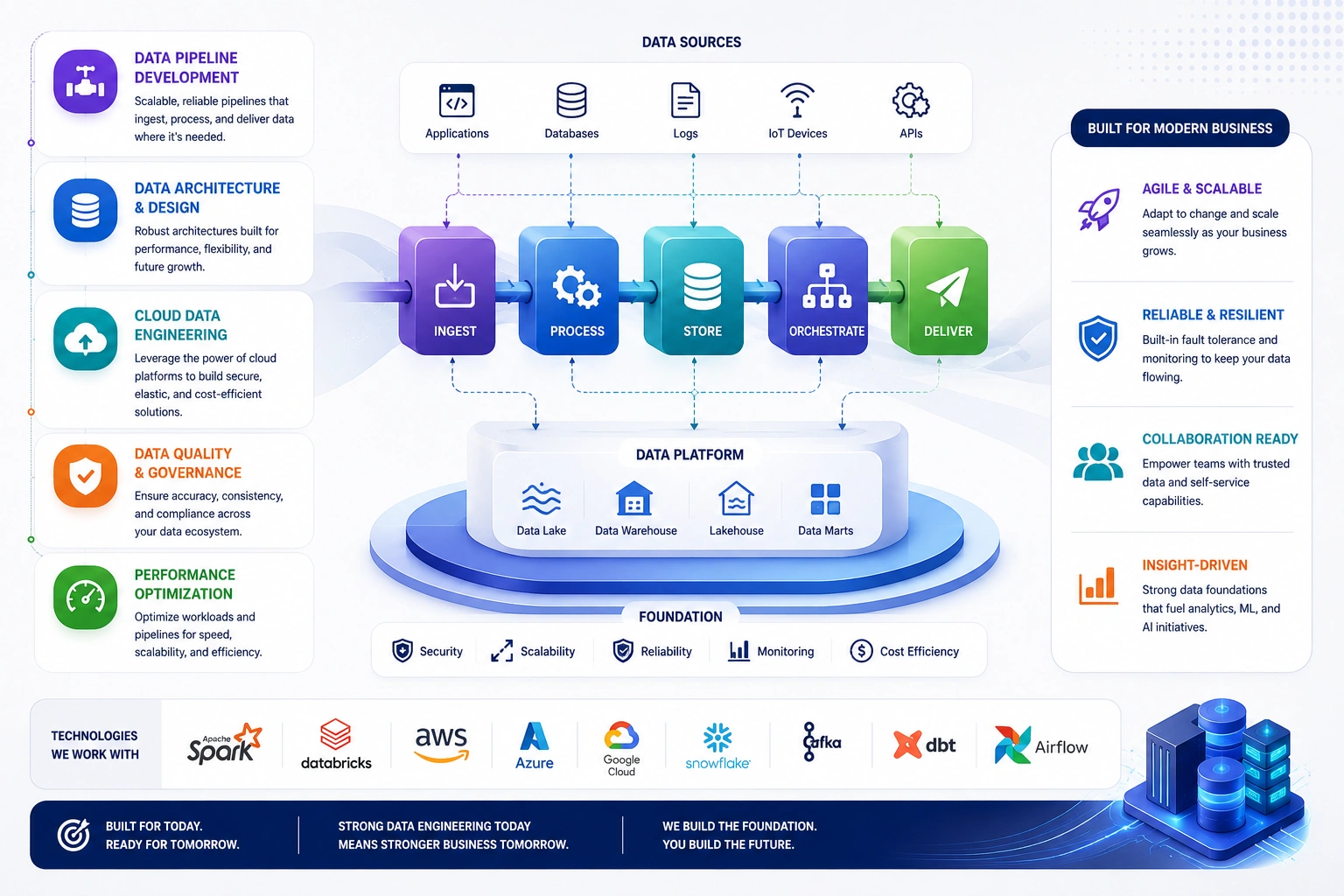
CCPL.ai (CONFRONTIERS CONCLAVE) builds and delivers six core data engineering solutions - each engineered around your specific data volumes, systems, and business requirements.
We design and build custom data pipeline architecture using Apache Spark, Kafka, Airflow, dbt, and cloud-native orchestration tools - processing structured, semi-structured, and unstructured data from CRMs, ERPs, APIs, IoT devices, and flat files. Every pipeline includes automated quality checks, alerting, and lineage documentation.
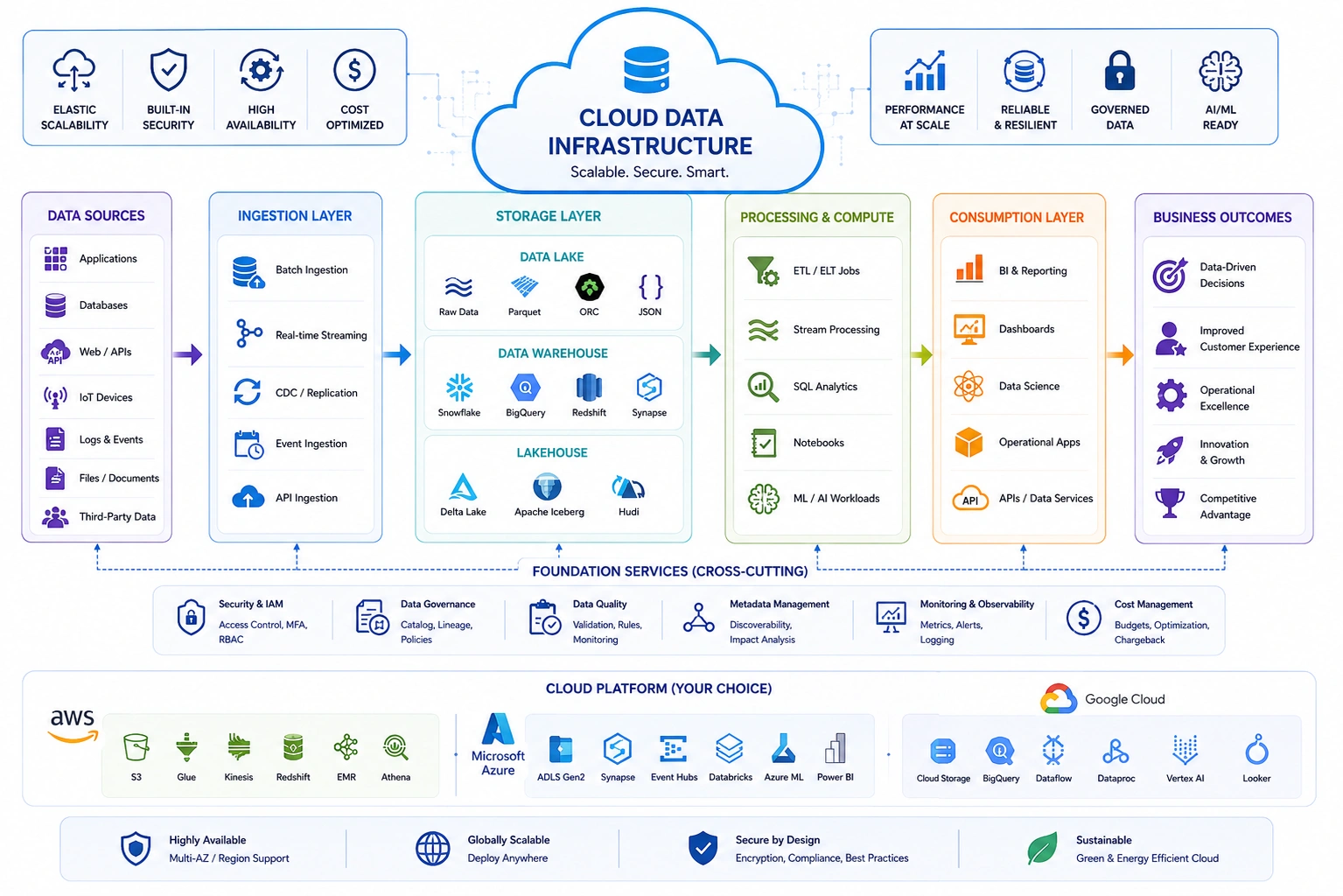
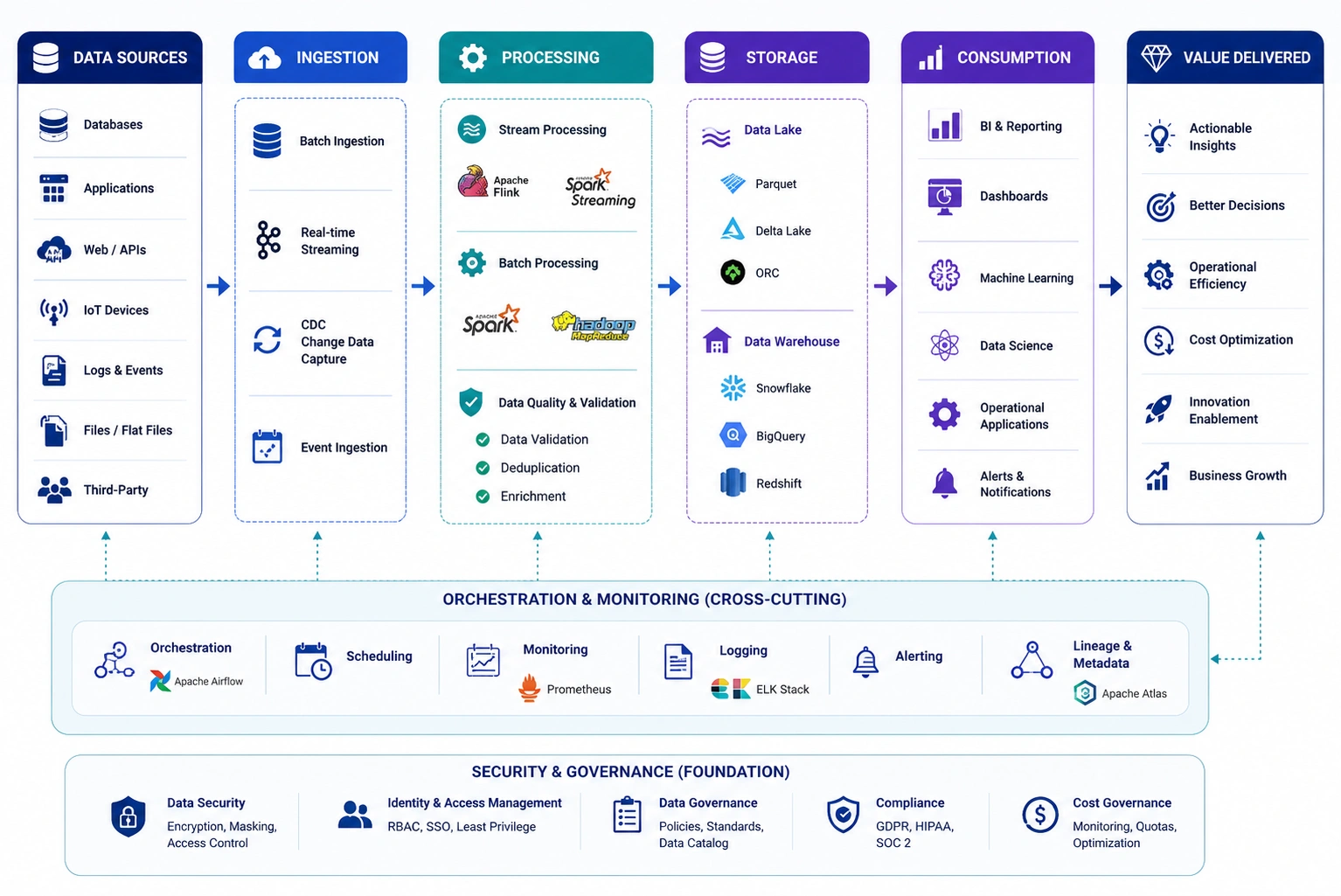
We build cloud data infrastructure on Snowflake, BigQuery, Redshift, Databricks, and Azure Synapse - right-sized to your actual workload rather than over-provisioned for theoretical peaks. Every environment includes cost controls, security configuration, and access management designed from day one.
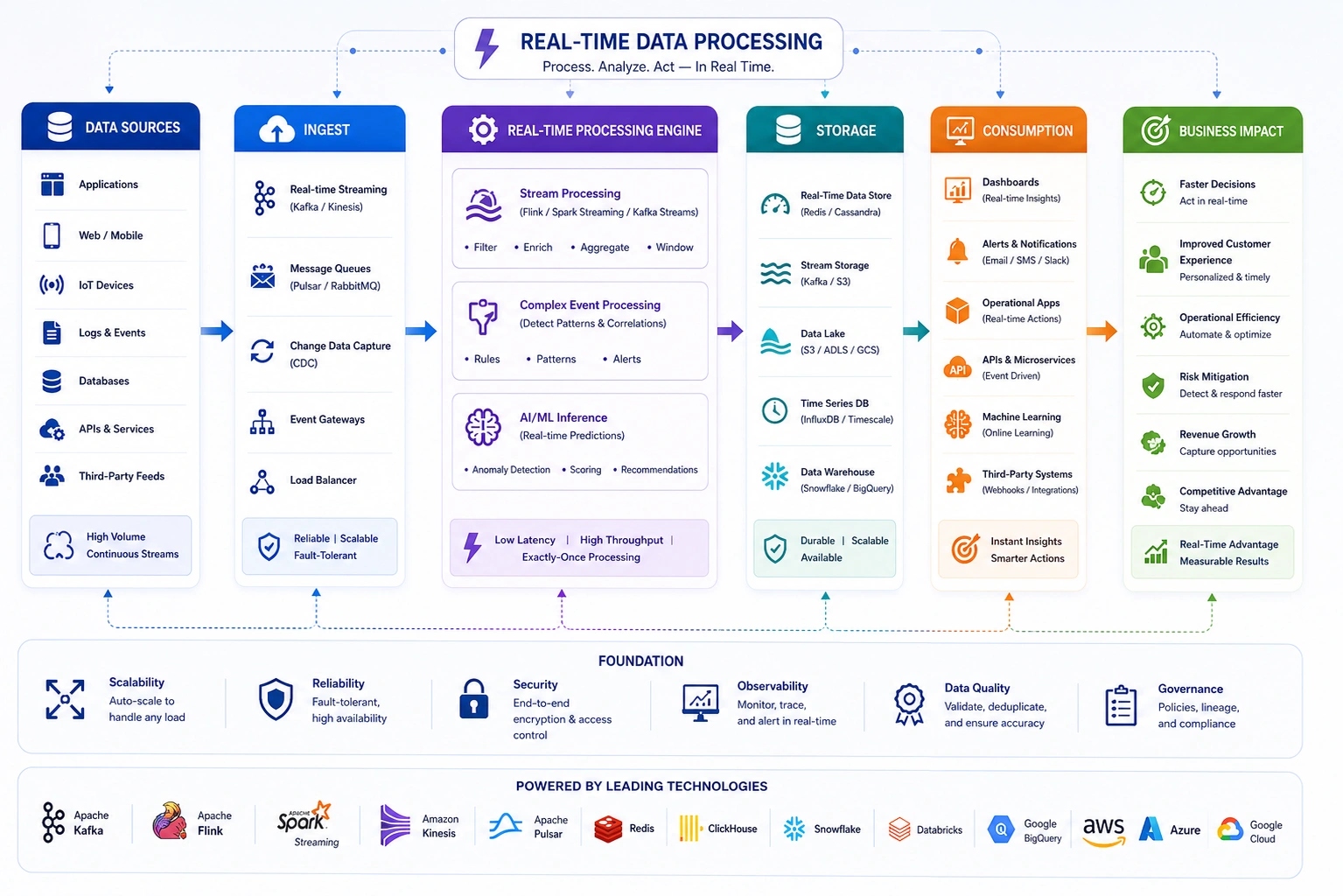
We build real-time data processing architectures using Apache Kafka, Apache Flink, AWS Kinesis, and Google Pub/Sub - processing millions of events per second with the reliability and fault tolerance production operational systems require. Streaming pipelines connect directly to your dashboards, AI models, and operational applications.
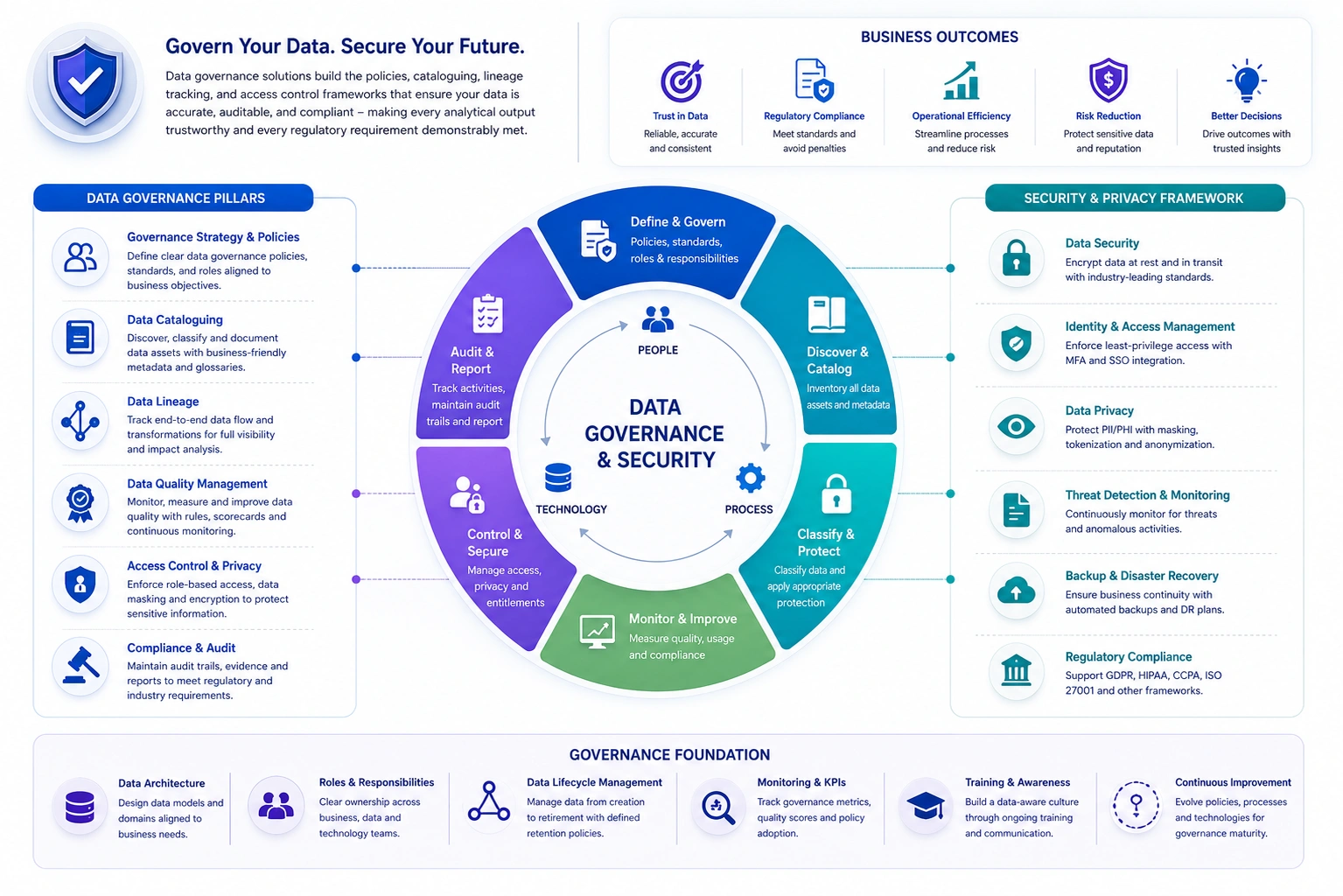
We implement data governance using Apache Atlas, Collibra, or Alation - setting up role-based access control across your data estate, automated quality monitoring, and the audit trail infrastructure that makes compliance reporting straightforward. Built for GDPR, HIPAA, and sector-specific regulatory frameworks.

We connect all major source systems into a unified data integration layer - CRMs, ERPs, databases, APIs, SaaS platforms, and legacy systems. For businesses undergoing broader platform transitions, our B2B migration services deliver the full migration alongside the data engineering - so infrastructure and data arrive in the new environment together.
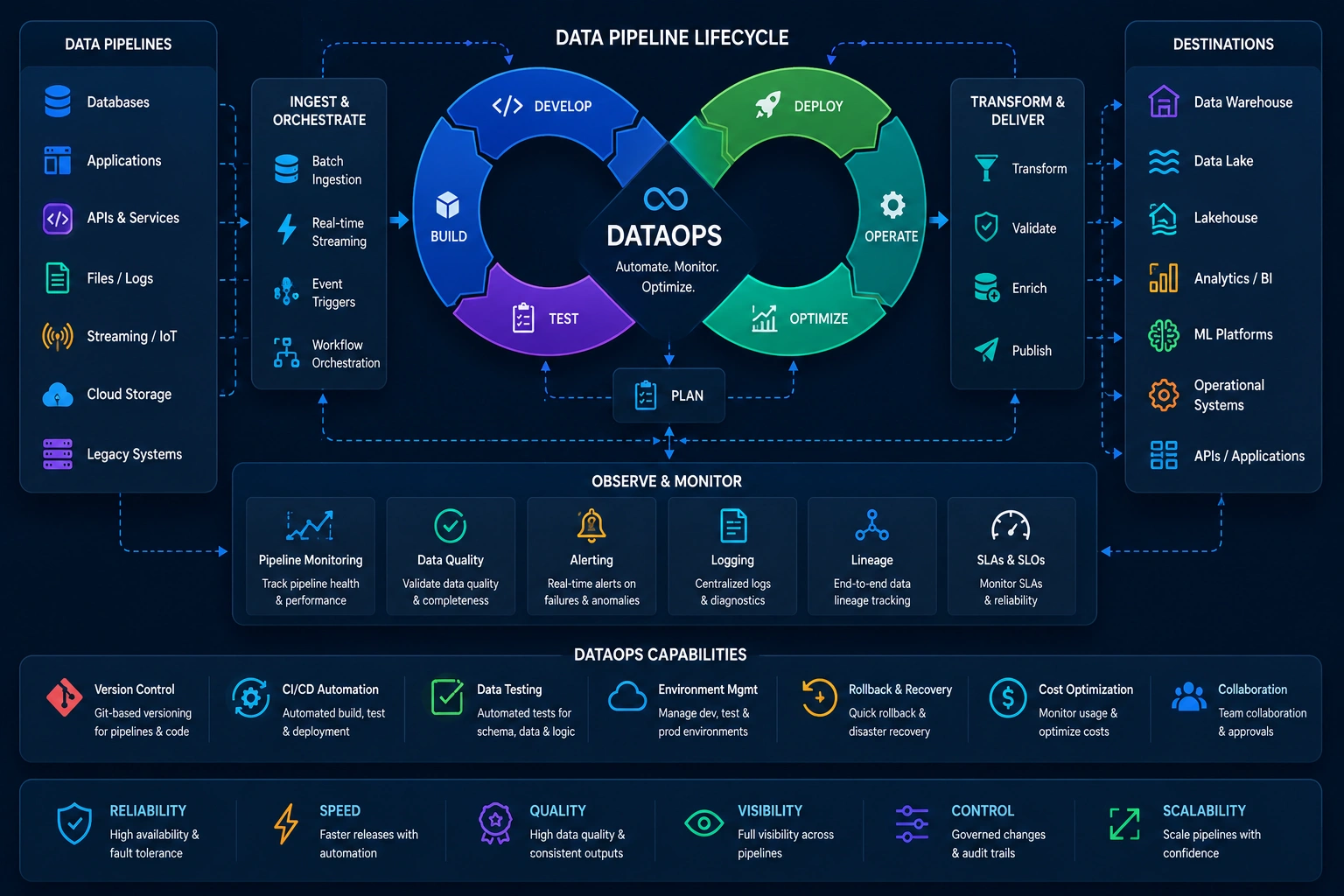
We set up CI/CD for data workflows, automated testing for data quality and schema validation, and comprehensive monitoring using Monte Carlo, Great Expectations, and custom dashboards. Every DataOps deployment gives your team full visibility and control over your entire data estate - with alerting before failures reach downstream consumers.
Industry-leading tools - selected for your specific workload, not applied as a standard template.
Real-time transaction data pipelines, risk analytics infrastructure, regulatory reporting data marts, and fraud detection data feeds - built under applicable compliance frameworks including SOX and Basel III.

HIPAA-compliant pipelines for patient data, clinical analytics infrastructure, EHR data integration, and real-time clinical monitoring feeds for operational and diagnostic applications.

Customer behaviour data infrastructure, inventory and supply chain analytics pipelines, real-time personalisation data feeds, and demand forecasting data platforms at scale.

IoT data ingestion and processing pipelines, predictive maintenance data infrastructure, and product analytics platforms - handling high-velocity sensor data at production-grade reliability.

SaaS operational data engineering, product analytics platforms, and scalable data infrastructure for technology businesses - built to grow with your user base and data volumes without manual re-architecture.
A specialist data engineering partner - production-grade infrastructure delivered by engineers who have built and operated large-scale data systems, not consultants who recommend tools and leave implementation to you.
